En este ambito la creación de los Datawarehouse tienen dos grandes gurús, por un lado el archiconocido Kimball con su modelo multidimensional, y por el otro el quizás menos conocido pero no menos importante Inmon.
Me he estado leyendo este artículo que la verdad aporta poco y no es mas que una revisión de todos los conceptos de un datawarehouse, pero que me ha servido para reflexionar cual es mi propio de creación de datawarehouse y cual sería el más apropiado para una metodología ágil
MODELING STRATEGIES AND ALTERNATIVES FOR DATA WAREHOUSING
Y me ha sorprendido comprobar que estoy mas de acuerdo con las tesis de Inmon que con las de Kimball, yo que he sido un fiel seguidor del primero
Aquí podemos ver dos típicas arquitecturas al "estilo Kimball"

El primer modelo es el utilizado en algunas implementaciones MOLAP puras en las que tenemos varios procesos ETL, que se conecta a diferentes fuentes de datos y generamos los diferentes datamarts dimensionales. Son generalmente datamarts independientes entre ellos para el uso de un solo departamento o incluso de una sola persona.
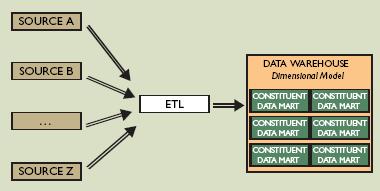 El segundo modelo es el Kimball mas corporativo en el que un proceso ETL nutre un espacio datawarehouse en el que se comparten las dimensiones entre diferentes puntos de vista y en el que los datamarts de cada departamento forman utilizando los hechos y las dimensiones ya establecidas para toda la compañia.
El segundo modelo es el Kimball mas corporativo en el que un proceso ETL nutre un espacio datawarehouse en el que se comparten las dimensiones entre diferentes puntos de vista y en el que los datamarts de cada departamento forman utilizando los hechos y las dimensiones ya establecidas para toda la compañia.Todo normal hasta aquí y perfectamente de acuerdo con ello, yo mismo he hecho decenas de dwh utilizando el dogma Kimball
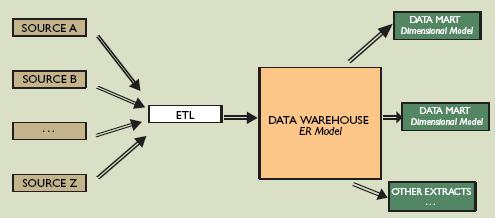
Pero miremos ahora el "estilo Inmon"
Coincide con Kimbal en un único proceso ETL que nutra un DWH corporativo, pero el que él nutre no es dimensional es un DWH basado en el modelo Entidad-Relación.
La idea de Inmon es que el modelo E-E mucho mas rico y adaptable que el multidimensional.
Una vez tenemos el DWH E-R corporativo generamos los datamarts dimensionales que queramos, y no solo eso, nos puede servir para crear cualquier otra extracción para cualquier otro sistema decisional, como puede ser para mineria de datos o para sistemas expertos, por ejemplo.
Lo que me gusta de Inmon es que no se cierra a un solo modelo y no solo eso, además su arquitectura mejora la trazabilidad decisional. Con ella podemos desgranar un valor en un KPI hasta una serie de análisis y reports que lo expliquen en detalle, tan en detalle como nos permiten los modelos E-R que tenemos en nuestros sistemas operacionales.
Parece maravilloso, pero el problema es que es mas costoso de mantener y de implementar. El de Inmon es un modelo que mira a largo plazo y para una metodología ágil el largo plazo es secundario. Para adaptarlo y no perder la agilidad de por ejemplo el primer modelo de Kimball, yo he utilizado a veces lo que he llamado la "Starting Area".
Si el proyecto necesita de una trazabilidad que llegue hasta el ultimo nivel de detalle, lo mejor es crear un capa que sea una copia exacta de los diferentes modelos relacionales de los que se nutre el modelo dimensional. Una simple BULK COPY nos servirá inicialmente, no hace falta unificar el modelo E-R de las diferentes fuentes origen en uno solo, eso es demasiado trabajo. La idea es dejar la semilla de una capa relacional por debajo del dimensional y que ambas crezcan de forma conjunta alo largo del proyecto.
Creo que esta sería la mejor opción para una metodología ágil, nos permitirá tener la rapidez del modelo Kimball y la visión de futuro del modelo Inmon.





20 comentarios:
Muy, muy interesante. ¿Podrías recomendar alguna bibliografia de ambos autores, bien libros bien artículos no de pago?
Muchas gracias.
puedes mirarte estos articulos
Data Warehousing: Similarities and Differences of Inmon and Kimball
Data Warehousing: Relational vs. Multi-Dimensional Data
o el libro de Inmon
Building the Data Warehouse
o el de Kimball
The Data Warehouse Toolkit
Un saludo
Hi Wiseman!!!!
Felicitarte por el contenido del blog... Enorme!
Cuando me pongo mirar los distintos temas de los que hablas me doy cuenta de que soy poseedor de una amplia ignorancia.....
Gracias por ampliar un poco mas mi vision. Creo que voy a tener trabajo para una temporada para poder asimilar todos los conceptos de los que hablan.
Me quito el sombrero...
A pesar de que trabaje contigo... que poco aprendi (o que poco me ensenyastes!)
Salu2 desde las islas!!
Pd: Comentario sin acentos :-(
Por cierto, Inmon tienes conceptos muy interesantes y utiles para poner en practica ;-)
es que no me escuchabas solo pensabas en irte a los U.K. a tus maravillosas islas :-D y no me prestabas atencioón
Aprovecha y comenta como esta el tema del BI por allí, y no te hagas el modesto que tu sabes mucho.
Hola,
Como siempre tus post son una provocación a la reflexión Jorge. Bajo mi punto de vista Lo que propone Inmon es esencial para poder realizar análisis globales o transversales de una compañía. Aún que a mi me parece que en otros campos ya hace tiempo que este aspecto se tiene claro. Por ejemplo en el mundo de las finanzas, ya que las multinacionales hablan siempre de la consolidación financiera. ¿No te parece que en el fondo es un poco lo mismo?
Bueno a parte de esto, también pienso que el Data Warehouse ER que propone Inmon, no tiene que por ser realmente un modelo ER sino que puede ser un modelo multidimensional (en adelante MMD) muy detallado y que no este en estado puro. Ya que realmente un modelo MMD detallado contiene prácticamente la misma información que el modelo ER pero organizado más con un enfoque de análisis, que en definitiva es un poco a lo que vamos con BI ¿no?
Bien pues si tomamos el MMD detallado como valido. Entiendo que los procesos que propone Kimball para realizar análisis y los que propone Inmon se acercan. Porque podemos realizar procesos de análisis por áreas de la empresa. Empezando por ejemplo, y típicamente por ventas. Desarrollar un proceso parecido al de Kimball en un MMD muy detallado (aplicando posteriormente las agregaciones necesarias) pero pensando ya en un Data Warehouse consolidado. Y así sucesivamente con todas las áreas de la empresa. Esto nos permitirá al mismo tiempo aproximar las metodologías ágiles a la propuesta de Inmon que a mi también me parece las más correcta.
Un Saludo,
Martí
PD. Un saludo para Josep M. también!!!!
Hola marti
No, no, Inmon propone exclusivamente un E-R, dada su garna versatilidad, si le pones un MDD, tendrás un semiestructuración y un producto cartesiano muy majo. Si lo implementas en ROLAP tendras que poner muchos agregados, y si lo implementas en MOLAP tendras un supercubo inmanejable.
Lo importante es segun Inmon tener un estructura flexible que nos lo da el E-R y a partir de ahí si quieres haz un dimensional o lo que te de la gana.
Un saludo
Hola Jorge
A mi parecer lo que realmente sugiere Inmon es un modelo normalizado e integrado que tendria 3 objetivos importantes:
1.- Integrar informacion operativa que puede encontrase en sistemas heterogeneos que vienen de tipologias (Motores de Base de Datos) de diferente proveedor (Una parte en Oracle, Otra en SQL Server, Otra en Db2 400, Archivo de Textos, Hojas de Calculo, etc), la cual debe ser integrada en un unico ambiente donde se alojara el datawarehouse (Muchos le llaman Stating Area pero a diferencia del ambiente de preparacion que normalmente no esta normalizado pocas veces es reutilizado en otros proyectos) para lo cual tiene muchos beneficios acerca de seguridad, reusabilidad, tiempo de proceso, eficiente, mantenimiento, tiempo de desarrollo, etc, lo que se llama Operative Data Storage.
2.- Agregar elementos de negocio que no se encuentran en los datos operacionales, yo pienso que existen 2 tipos de atributos que permiten realizar un analisis mas profundo de la informacion, le llamo Atributos Calificadores y son de 2 tipos:
. Calificadores de Atributos, Ejemplo:
Clientes
Buenos, Malos, Regualares
Proveedores
VIP, negociadores, Reclamadores
. Calificadores de Indicadores
Ejemplo:
Ventas Altas, Medias, Bajas
Cantidad de venta excesiva, normal, pobre.
Compra regular, contante o por impulso.
Nivel Continuidad: Primera Venta, Compro hace 2 meses, Compro hace 3 Meses, Compro hace 4 Meses.
Si nos damos cuenta la carga de estos atributos calificadores se hacer ejecutando una serie de procesos que responden a reglas de negocio y que muchas veces se requiere procesar muchos registros para determinar que calificacion tedra el atributo, l tenr un modelo normalizado ER intergrado y atomico permite reutilizar estos atributos para otros datamart.
Si desean conocer mas sobre atributos calificativos los invito a visitar mi pagina web www.datamarting.org/info
3.- Capacidad de hacer drill forzados que cuando queramos ver datos detalle como el telefono del cliente, el numero de la factura o pedido, la direccion del cliente puedas ir a estas tablas y no estar buscandolo en la data original que podria originar un problema de seguridad o perjudicar el tiempo de respuesta en los sistemas transaccionales....
Las desventajas es que necesitaras mas espcacio y tiempo para hacer esta tarea..... Le paso tambien la voz que existe un ETL que te ayuda a hacer esto de manera muy facil www.bitool.com este software lo hice yo asi que es bueno!!! jajaja
Aprovecho para invitarlos a participar de este proyecto llamado www.datamarting.org pero la web estoy haciendola y tengo un borrador en www.datamarting.org/info
El datamarting es una metodologia alineada al CMMI Nivel 2 que con un grupo de consultores estamos desarrollando y que estoy seguro que con su ayuda podemos hacelo cada vez mejor....
Piensa que Inmon es el padre del concepto datawarehouse que tu mi bien has resumido, mientras que Kimball vino despues a semiestructurarlo con su concepto multidimensional.
La Staging Area en el modelo multidimensional(donde se realizan los procesos ETL) debe de ser totalmente volátil, al final de los procesos ETL debe desaparecer una vez nutrido el datamart, por eso el modelo de Inmon nos da un punto mas de apoyo partiendo de E-R.
Le he pegado un ojo a tu metodología y veo que coincides mucho con Kimball, aunque veo que tambien habeis detectado la importancia del usuaio. Os animo a que sigais por ese camino, creo que vais bien
Jorge veo que si mantienes activo tu blog, lo del staging area me dejaste con duda, cuando vi por primera vez sunopsis se referia a Staging Area como el ambiente que te permite integrar datos de diferentes fuentes o al ambiente donde se cruzan los datos.... sin embargo alguien una vez me comento que deberiamos tener un staging area o Operative Data Storage (ODS) no volatil de tal forma de que si en otro datamart se requiere nuevamente esos datos no tengan que nuevamente preparalos sino solo usarlos !!! claro si tienes el dinero para tenero aguantardos en u disco por buen tiempo o si tienes constantes datamart que se hacen por proveedores diferentes y algunos en momentos comunes (caso bancos y telecom)....
Espero que seas un usuario frecuente cuando tengamos lanzado el portal del datamarting y ojala te animes a ser un miembro activo!!!
Si, es cierto, no conocia la terminología ODS a mi me gusta mas llamarla Starting Area poruqe es el punto de partida del proceso ETL(la Staging es la volatil). Con el ODS que me comentas parece que lo que se quiere reutilizar son los procesos de limpieza de la ETL y supongo que algunos de agregacion (aqui estoy especulando vilmente). Cuando yo he utilizado la Starting Area lo he hecho a modo de embrión de un MasterData corporativo, para unir conceptos de diferentes sistemas despues de limpiar los datos, no habia pensado en las agregaciones.
Cuando mezclas Inmon con Kimbal te acabas dando cuenta que es necesaria esa capa.
Ya tengo tu pagina fichada y estaré encantado de participar
Por cierto existen actualemtne productos que te mantienen en memoria los mapeos de los procesos ETL, pudiendo tener una capa de unificación de los diferentes ambientes operacionales en memoria comportándose como uno solo.
Aprovecho para lanzarte un pregunta ¿Que piensas que hará Oracle con Sunopsis?
La famosa nuve de datos de qlikview.... por ahi vi otros productos que hacen una especie de cubo en memoria... no he usado pero creo que es un buena evolucion que de repente podria ser la tendencia por que para ser sinceros los ETL se vuleven muy omplicados y demoran muchio tiempo hacer sin considerar el alto nivel de riesgo que los datos descuadren.
Acerca de la compra de oracle a sunopsis yo creo que sera su nueva herramienta de ETL por que es mil veces mejor que datawarehouse builder, no creo que lo haya comprado para sacarlo del mercado por que hubiera pensado en data stage y no tanto en sunopsis.
Y gracia spor querer participar, te cuento que tenemos amigos de etica soft en espania que tambien participan en est proyecto de datamarting....
otra cosa conoces microstrategy, te gusta que piensas de ese producto?
tambien queria que te des el tiempo de probar un ETL que tengo que se parece mucho al Sunopsis por el tma de los KM a ver si te das un tiempo y via msm te paso el link y te ayudo a instalarlo para que lo pruebes y me des tus comentarios.
Un gusto conocerte y siempre dispuesto a compartir informacion.
Hola a todos,
Es muy dificil explicar estos conceptos, por este medio y ademas para ser BIEN entendidos por todos, por ello valoro y seguro que los demas tambien este blog.
Además de todo lo dicho y de las "guerras" Kimball vs Inmon. Existe un factor claro, la cantidad de personas que diseñan este tipo de sistemas, en especial en los ultimos años, sin tener realmente conocimiento claros y ademas sin visión del sector o negocio donde lo aplican.
El diseño de estrellas, lo habitual, es barato a corto plazo, pero lamentablemente suelen estar poco relacionadas e incluso en algunas ocasiones a una necesidad (trsitemente informe) viene asociada una estrella, a otro necesidad otra estrella... ¡¡¡ VAMOS BIEN !! si, si ... directos a estrellarnos. Pero posiblemente el problema no salga a la luz hasta pasado algun tiempo, es algi así como un cancer... tarda en dar la cara.
Las BBDD propietarias son maravillosas para lo que son. Pero ojo son productos cartesianos (habitualmente) y por ello tienen unas ventajas y graves carencias. Permiten algunas cosas muy interesante, como que la suma de los hijos no tenga la obligada necesidad de ser igual a la del padre. Pues en el fondo da igual, cada producto, celdilla o como queramos llamarlo tiene metido ya calculado su dato.
Estas estructuras no soportan unos volumenes medianamente importantes y logicamente de imposible utilidad para solucionar un amplio DW corporativo. Ojo y atención ante la necesidad de cambios... posiblemente borrado de todo y regeneración.
Los modelos ROLAP, entendiendolo como modelos OLAP bajo gestores relacionales son los únicos cimientos posibles a grandes proyectos. Despues podemos discutir, quien quiera que yo no, sobre que modelo de datos a usar. La experiencia no dice, que loas estrellas se quedan cortas, pero los modelos copo de nieve son una solución muy valida, por no decir la única.
Otra cosa son los mensajes que nos mandan lo fabricantes de software, pues logicamente tienen que defender sus productos. En ello incluyo a Kimball, pues tiene soluciones y negocios relacionados con las estrellas.
Casi todas las herramientas corren, sobre ROLAP en copo de nieve (para entendernos), pero solamente alguna destaca claramente, por ello han sido fuertemente criticadas.
En el fondo un modelo copo de nieve desnormalizado a tope (insultantemente desnormalizado) y quedandonos exclusivamente con las tablas de cada dimensión de mayor detalle o profundidad es lo mismo que una estrella.
Al final todo es más de lo mismo, pero estrcturado de una forma diferente. Es más puedes hacer un modelo E/R con modelo copo de nieve 100% normalizado en tercera forma normal... que la desnormalización es una tecnica, en este tipo de modelos, de optimización, no una obligación y dependera de la herramienta de explotación que usemos, pues algunas no haran ni caso de las dernormalizaciones intelligentes.
Siento el rollo, pero a aquellos que nos apasiona este mundo, empezamos a escribir y no paramos.
Para todos aquellos que deseis comentar, ampliar o clarificar alguna cuestión os facilito mis datos. Pues logicamente escribir sobre esto es francamente dificil, necesitaria una pizarra y poner ejemplos.
Estoy a vuestra entera disposición.
Gracias Jorge y hasta pronto.
Chema Arce.
www.josemariaarce.es
jmarce@movistar.net
Gracias a ti Chema por compartir tu experiencia
Estoy totalmente de acuerdo contigo
Es un placer leerte, como se nota que tambien eres docente.
Hola Chema
Hace tiempo que no entraba a este blog que se convirtio en Foro.
en los años que llevo en este negocio he modelado usando varios esquemas:
Copo de nieve (mi ingreido)
Estrella (Comercialmente hablando un buen negocio)
Costelacion de estrellas (Es una estrella que quiere ser copo de nieve)
Tormenta de nieve ( Un copo de nive que se acompleja de si misma y quiere ser estrella)
En realidad el esquema de modelamiento no es tan importante cuando tienes problemas con la herramienta de explotacion ya que soporta ern forma mas eficiente una u otra.
Claro que por temas comerciales muchos fabricantes dicen soportar una u otro esquema pero en la practica se tiende a usar el que recomienda por tener mejores resultados.
A mi me gusta el copo de nieve normalizado ya que con este modelamiento puedo llegar a crear modelos BDS (Business Data Storage) o cubos sin problemas... convertir de Copo de Nieve a estrellas es facil cosa que no lo es al reves.
Un abraso y los invito a descargar un producto que he desarrollado que utiliza al excel y permite pivotear, muy buena para dictar cursos, talleres o pequeños proyectos de BI sin complicarte la visa con la tecnologia.
"A equino donado no se le obculta el incisivo"
Un abrazo
Jose Zarate
www.bitool.com
>Compra o vendes loque quieras con www.superavisos.com
Jorge, es idea mia o acabas de perder una apuesta? Actualizacion del post 8 de Junio, a escasas horas de firmar con sangre unas birras!
jejeje!
Antonio
te debo una birra je je je,pero no es lo que piensas, es que necesitaba los backtrack de ese post para mi doctorado y no he teneido mas remedio que actualizarlo para poderlo poner, pero te debo una birra, una apuesta es una apuesta
Me gustó muchísimo la discusión. :)
Publicar un comentario