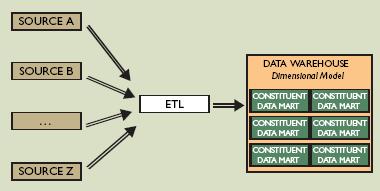
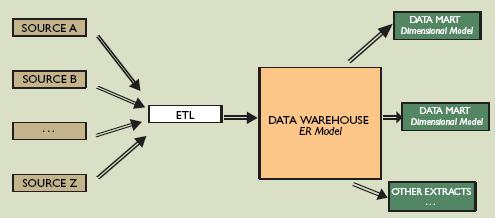
En el anterior Post introduje como nació la Starting Area (STA de ahora en adelante).
Esta idea ha ido evolucionado y la STA cumple actualmente 4 funcionalidades y posee 2 características (que ya avancé en el anterior post)
 La primera de ellas la pudimos ver en el anterior post. Se trata de tener siempre "llenos" los primeros pasos de los procesos ETL, y no borrar esa información. Para ello cogemos el último nivel de agregación desde el que construimos el DWH. Obviamente como vamos a dejar la información de forma permanente la STA debe estar obligatoriamente en una base de datos relacional diferente a la Staging Area (STG) para poder optimizarla y realizar tunning de forma separada en el caso de que el volumen de datos así lo hiciera recomendable.
La primera de ellas la pudimos ver en el anterior post. Se trata de tener siempre "llenos" los primeros pasos de los procesos ETL, y no borrar esa información. Para ello cogemos el último nivel de agregación desde el que construimos el DWH. Obviamente como vamos a dejar la información de forma permanente la STA debe estar obligatoriamente en una base de datos relacional diferente a la Staging Area (STG) para poder optimizarla y realizar tunning de forma separada en el caso de que el volumen de datos así lo hiciera recomendable. Obviamente todos estos procesos necesitan de una unificación del modelo cuando las fuentes de datos son heterogeneas. Por ejemplo si estamos unificando el concepto "Cliente" podemos tener un modelo E-R de Cliente en el ERP que nada tenga que ver con el "Cliente" del CRM y que en la aplicación de gestión comercial tenga otro significado muy distinto. Obviamente desde el punto de vista decisional nosotros tenemos un único "Cliente" así pues en la STA, cuando las fuentes de datos son heterogeneas ,nos quedamos con el último nivel de detalle pera una vez unificado el modelo. Así esta tabla puede ser unificada no solo en la parte decisional sino que cualquier otra aplicación que quiera hacer uso de "Clientes" puede intorducirla como su fuente de datos operacional, de esta manera tenemos el embrión de un MasterData de la organización que mas adelante pueda servirnos tanto para la parte de sistemas de información transaccionales, como para los sistemas de información decisionales. Es una buena manera de empezar a difundir el concepto de MasterData en aquella empresas que no están maduras.
Obviamente todos estos procesos necesitan de una unificación del modelo cuando las fuentes de datos son heterogeneas. Por ejemplo si estamos unificando el concepto "Cliente" podemos tener un modelo E-R de Cliente en el ERP que nada tenga que ver con el "Cliente" del CRM y que en la aplicación de gestión comercial tenga otro significado muy distinto. Obviamente desde el punto de vista decisional nosotros tenemos un único "Cliente" así pues en la STA, cuando las fuentes de datos son heterogeneas ,nos quedamos con el último nivel de detalle pera una vez unificado el modelo. Así esta tabla puede ser unificada no solo en la parte decisional sino que cualquier otra aplicación que quiera hacer uso de "Clientes" puede intorducirla como su fuente de datos operacional, de esta manera tenemos el embrión de un MasterData de la organización que mas adelante pueda servirnos tanto para la parte de sistemas de información transaccionales, como para los sistemas de información decisionales. Es una buena manera de empezar a difundir el concepto de MasterData en aquella empresas que no están maduras. Muchas veces desde el DWH necesitamos vincular con información de detalle cuyo detalle tenemos que ir a buscarlo al operacional, por eso nos puede llegar a interesar tener algún repositorio con esa información ya almacenada (siempre que no estemos tratando de información a tiempo real). Por ejemplo, si queremos saber el número de incidencias de producción la semana pasada lo tenemos fácil, pero si queremos buscar una descripción de los incidentes de gravedad 1 de esa misma semana para ponerlo en el Informe, entonces deberíamos ir al operacional. Para facilitar esto lo que podemos hacer es traernos un nivel de detalle mas bajo que el que estamos utilizando en el DWH y vincularlo con la base de la estrella al mas puro estilo Inmon, como Reporting. Alguien podría decir que esto no es mas que un ODS (Operational Data Storage) y le daría la razón pero con un matiz, y es que los ODS carga información operacional agregada y yo cargo información de detalle muy bajo, ya que la información típicamente agregada del ODS para mí es parte del modelo del DWH al combinar Inmon y Kimball en la base de la estrella.
Muchas veces desde el DWH necesitamos vincular con información de detalle cuyo detalle tenemos que ir a buscarlo al operacional, por eso nos puede llegar a interesar tener algún repositorio con esa información ya almacenada (siempre que no estemos tratando de información a tiempo real). Por ejemplo, si queremos saber el número de incidencias de producción la semana pasada lo tenemos fácil, pero si queremos buscar una descripción de los incidentes de gravedad 1 de esa misma semana para ponerlo en el Informe, entonces deberíamos ir al operacional. Para facilitar esto lo que podemos hacer es traernos un nivel de detalle mas bajo que el que estamos utilizando en el DWH y vincularlo con la base de la estrella al mas puro estilo Inmon, como Reporting. Alguien podría decir que esto no es mas que un ODS (Operational Data Storage) y le daría la razón pero con un matiz, y es que los ODS carga información operacional agregada y yo cargo información de detalle muy bajo, ya que la información típicamente agregada del ODS para mí es parte del modelo del DWH al combinar Inmon y Kimball en la base de la estrella.Este nivel de detalle bajo nos puede ayudar también a crear el MasterData y nos da esa capacidad de reporting complementaria al DWH sin que tengamos que molestar a los operacionales.
 La STA como he dicho tiene un repositorio diferente de la STG y obviamente del DWH, así que podemos lanzar los procesos de carga de la STA con una periodicidad mucho mas pequeña que no la del DWH limpiando y puliendo los datos antes de hacer la carga definitiva del DWH. Esto nos da la posibilidad de detectar los errores antes de lanzar los procesos definitivos y mas costosos, mejorando la calidad del dato y los tiempos de los procesos de carga.
La STA como he dicho tiene un repositorio diferente de la STG y obviamente del DWH, así que podemos lanzar los procesos de carga de la STA con una periodicidad mucho mas pequeña que no la del DWH limpiando y puliendo los datos antes de hacer la carga definitiva del DWH. Esto nos da la posibilidad de detectar los errores antes de lanzar los procesos definitivos y mas costosos, mejorando la calidad del dato y los tiempos de los procesos de carga.De esta manera podemos construir escenarios en los que la STA se cargue diariamente y el DWH mensualmente. La mayoría de los posibles problemas de calidad del dato tienen 30 oportunidades de ser detectados antes de cargar el DWH.
Estas son las funcionalidades de la Starting Area, en el próximo (el último de esta trilogía) comentaré como construirla y sus dos características: