En este ambito la creación de los Datawarehouse tienen dos grandes gurús, por un lado el archiconocido Kimball con su modelo multidimensional, y por el otro el quizás menos conocido pero no menos importante Inmon.
Me he estado leyendo este artículo que la verdad aporta poco y no es mas que una revisión de todos los conceptos de un datawarehouse, pero que me ha servido para reflexionar cual es mi propio de creación de datawarehouse y cual sería el más apropiado para una metodología ágil
MODELING STRATEGIES AND ALTERNATIVES FOR DATA WAREHOUSING
Y me ha sorprendido comprobar que estoy mas de acuerdo con las tesis de Inmon que con las de Kimball, yo que he sido un fiel seguidor del primero
Aquí podemos ver dos típicas arquitecturas al "estilo Kimball"

El primer modelo es el utilizado en algunas implementaciones MOLAP puras en las que tenemos varios procesos ETL, que se conecta a diferentes fuentes de datos y generamos los diferentes datamarts dimensionales. Son generalmente datamarts independientes entre ellos para el uso de un solo departamento o incluso de una sola persona.
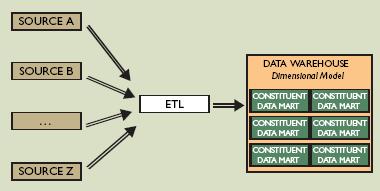 El segundo modelo es el Kimball mas corporativo en el que un proceso ETL nutre un espacio datawarehouse en el que se comparten las dimensiones entre diferentes puntos de vista y en el que los datamarts de cada departamento forman utilizando los hechos y las dimensiones ya establecidas para toda la compañia.
El segundo modelo es el Kimball mas corporativo en el que un proceso ETL nutre un espacio datawarehouse en el que se comparten las dimensiones entre diferentes puntos de vista y en el que los datamarts de cada departamento forman utilizando los hechos y las dimensiones ya establecidas para toda la compañia.Todo normal hasta aquí y perfectamente de acuerdo con ello, yo mismo he hecho decenas de dwh utilizando el dogma Kimball
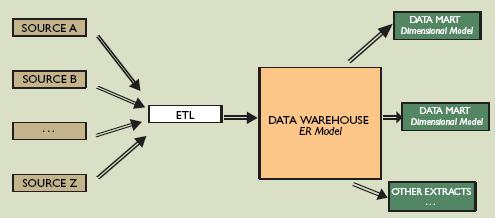
Pero miremos ahora el "estilo Inmon"
Coincide con Kimbal en un único proceso ETL que nutra un DWH corporativo, pero el que él nutre no es dimensional es un DWH basado en el modelo Entidad-Relación.
La idea de Inmon es que el modelo E-E mucho mas rico y adaptable que el multidimensional.
Una vez tenemos el DWH E-R corporativo generamos los datamarts dimensionales que queramos, y no solo eso, nos puede servir para crear cualquier otra extracción para cualquier otro sistema decisional, como puede ser para mineria de datos o para sistemas expertos, por ejemplo.
Lo que me gusta de Inmon es que no se cierra a un solo modelo y no solo eso, además su arquitectura mejora la trazabilidad decisional. Con ella podemos desgranar un valor en un KPI hasta una serie de análisis y reports que lo expliquen en detalle, tan en detalle como nos permiten los modelos E-R que tenemos en nuestros sistemas operacionales.
Parece maravilloso, pero el problema es que es mas costoso de mantener y de implementar. El de Inmon es un modelo que mira a largo plazo y para una metodología ágil el largo plazo es secundario. Para adaptarlo y no perder la agilidad de por ejemplo el primer modelo de Kimball, yo he utilizado a veces lo que he llamado la "Starting Area".
Si el proyecto necesita de una trazabilidad que llegue hasta el ultimo nivel de detalle, lo mejor es crear un capa que sea una copia exacta de los diferentes modelos relacionales de los que se nutre el modelo dimensional. Una simple BULK COPY nos servirá inicialmente, no hace falta unificar el modelo E-R de las diferentes fuentes origen en uno solo, eso es demasiado trabajo. La idea es dejar la semilla de una capa relacional por debajo del dimensional y que ambas crezcan de forma conjunta alo largo del proyecto.
Creo que esta sería la mejor opción para una metodología ágil, nos permitirá tener la rapidez del modelo Kimball y la visión de futuro del modelo Inmon.





